Prophia Copilot - Ai Assistant
Role: Product Designer (sole designer on project)
Duration: 2 months
Team: PM, Front-end developer and Back-end developer

CONTEXT
In light of recent advancements in AI, there is a sense of urgency in coming to the forefront of AI by leveraging LLMs in experiences tailored to fit PropTech needs - something current broader solutions don’t have the qualified data for or the industry knowledge to apply successfully. Prophia is uniquely positioned to tackle this problem of driving specificity to otherwise broad-use-only AI applications.
One of the most common pains of Prophia users is quickly getting answers to questions that are painstakingly difficult to hunt for due to the multitude of documents and volume of data that they need to survey to get portfolio, tenant, and leasing answers. Their current methods rely heavily on manual processes, cross-organizational alignment, and expensive external expert assistance.
Creating an AI assistant that tailors to CRE-specific questions using trusted data would establish Prophia as the market leader in Generative AI for CRE.
PERSONAS
Primary Persona:
External Users:
Executives and C-Suite
To be able to ask high level questions about anything in their portfolio and find the answer without having to dive into individual buildings or documents
Asset Managers
To be able to ask more detailed questions about the assets they are overseeing
Property Managers
To be able to get document specific answers in one place instead of going into each document
Secondary Persona:
Internal Users
To similarly find answers for our customers and pull data quickly in one place instead of having to go searching into individual assets and documents
Goals
Creating an AI assistant that tailors to CRE-specific questions using trusted data would establish Prophia as the market leader in Generative AI for CRE.
How might we analyze and digest all the data we capture to tailor an AI assistant to output accurate answers to our user’s questions about their portfolio?
RESEARCH + DISCOVERY
Initial Research and Discovery
Initial Challenges and Assumptions
AI team is not able to create the ai assistant to pull data from both document data and higher level portfolio data
Have to split out the experiences
Portfolio Copilot:
This is a text-to-SQL based solution
This is not a conversational experience
Queries include all tenants and buildings with essential information on platform to date for the account
Queries will be limited to the data outlined
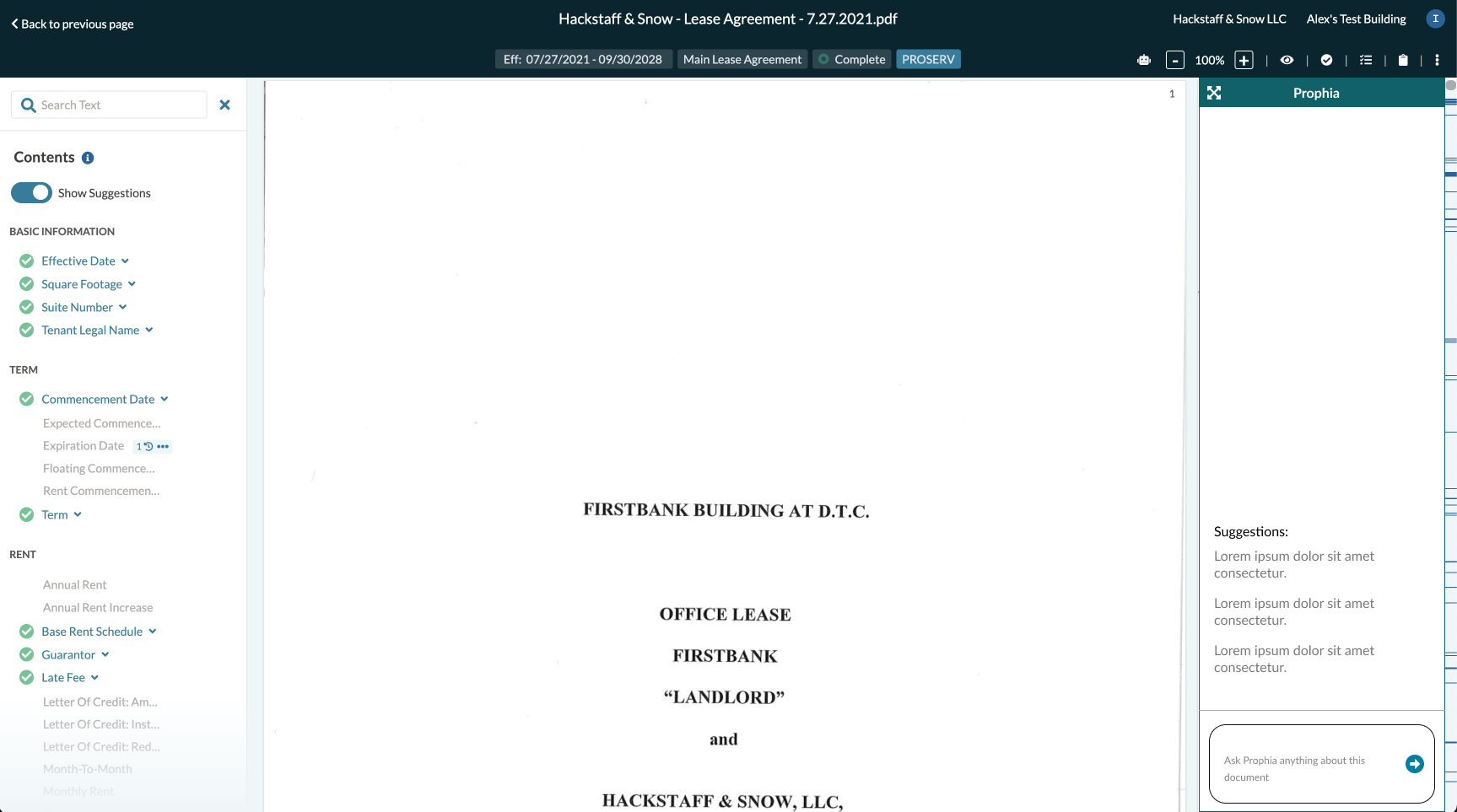
Document Copilot:
We will break apart each document into smaller sections and embed each section individually. Embedding converts text into 1k+ numbers (also known as vectors)
We will then embed the question the user types in, then find the closes document embeddings to that question
We pass those closest embeddings (the context needed to answer the question) to the LLM and have it generate a response
Feature Discovery
A look at other AI Assistants
ChatGPT
Claude
Microsoft Copilot
Initial Iterations





Designer Notes:
Looking for a streamlined experience that folks are used to
Need a way to narrow down data that is being searched to get a more accurate answers and faster
Need to have vs. nice to have features (MVP)
Question history
Setting parameters around the data
Suggestions
pre-made vs. ai curation
Two separate experiences are being created but how can I design the experience to carry over to both features?
Designs & USER TESTS
Document Copilot





Portfolio Copilot








User Research
Logistics
Interview 5 different users across 3 different orgs
Customer teams will find appropriate users that align with the target use case and organize 1 hour Zoom meeting - i.e. Property and Asset Managers, as well as executive personas that align with the types of questions that each of the co-pilots cater to
Interviewees will be asked to share their screen (Prophia only)
Interviews will be led by John and Sidd
Interviews will be recorded (upon consent)
Goals
Learn if users can use copilot to assist in their job function
Understand met/unmet expectations that will lead to functionality or UI/UX improvements
See how different users (PM, AM, CEO) use copilot
Introduce alpha testers to the tool
Identify prospective testers for long-term independent testing - i.e. Users who will independently test at least one of the co-pilots for a period of 2-4 weeks with the goal of PM/AI teams gathering prompt data (recorded automatically) and long-term use qualitative feedback
Key Takeaways
All users understood how to use the ai assistant
Portfolio Copilot is harder to understand because the answers are given in sql
Document Copilot was seen as the most valuable and ready to use feature
All users saw the answers but they wanted to be able to drill down into how the answer was formulated or where in the document the value is coming from
ADDITIONAL ENHANCEMENTS**
Character Limits For Question
The way the AI team created portfolio copilot backend, there is a limit to how many characters can be used. Needed a design to set the guardrail
Feedback Selections
Incorrect Answer
Incomplete Answer
Lacking Continuity
Inappropriate Answer
Wrong Assets Selected
Additional Feedback
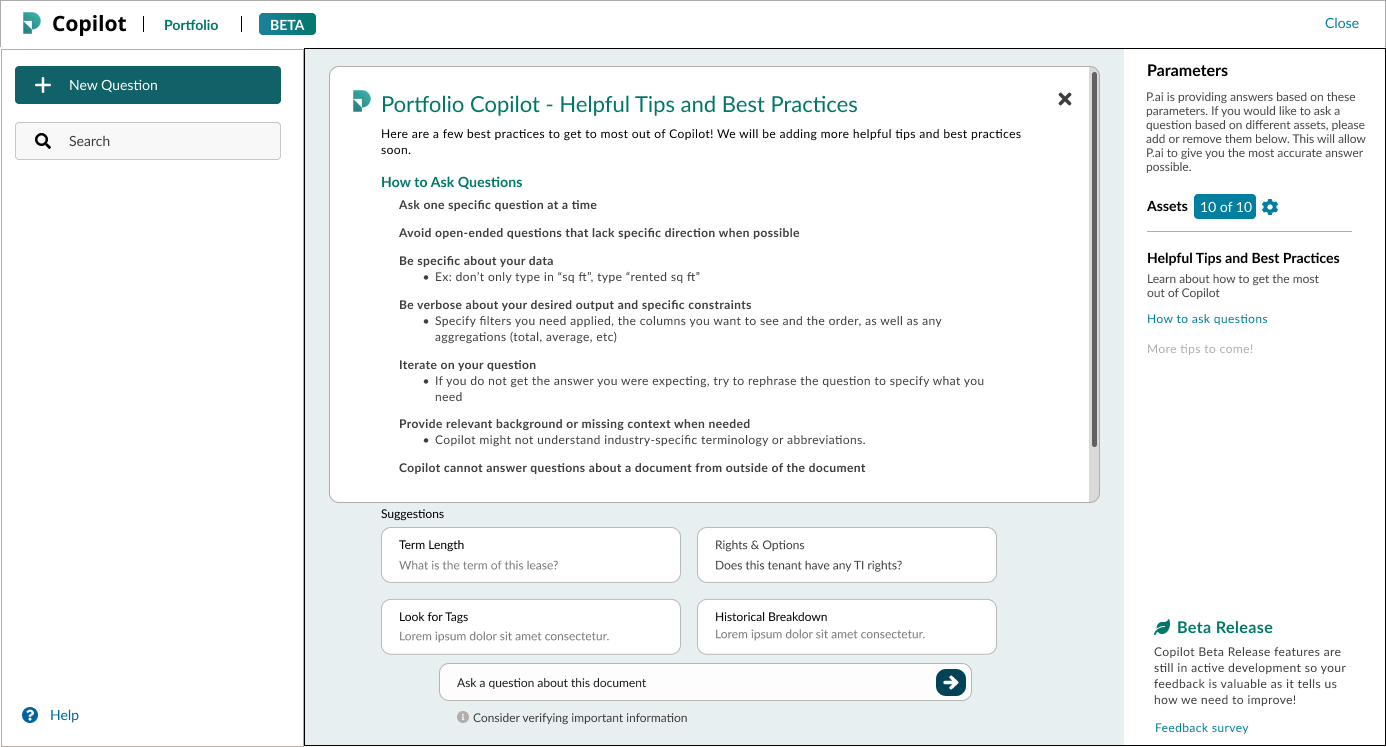
Disclaimer
“Consider verifying important information”
Info icon on hover:
Disclaimer
Responses are generated by an AI assistant. While AI can provide helpful information, the accuracy and validity of its output should be verified before relying on it.
Welcome Modal
A starting point for all users, it allows us to cover our basis to let users know that it wont be 100% accurate
Allows users to know what to expect
Tips & Best Practices
A curated list of tips and best practices to teach users how to format their questions to get the best experience
FEATURE RELEASE
Document Copilot was the only feature that was working properly and could be used as intended. I suggested that we release document copilot to all users to get more data around what questions are being asked and see how our user go about using copilot on a daily basis.
I recommended that we hold on the portfolio copilot because the answers weren’t accurate enough and the AI team had a bit more to go before we do a wide release. I also suggested us giving a few customers access so that we could still get some insight on how our customers would want to use it. As much as I try to help users narrow the parameters to assist the accuracy of answers, it is not enough to feel reliable to use regularly.